Building a Player Tracking Pipeline for NFL All-22 Film
Zero-shot player detection on NFL coaching footage using SAM3 and SAM2.1. What I built, what broke, and what the output looks like.
The NFL does not make coaching film openly available. Access requires an NFL Pro subscription, and the video itself is served through an authenticated HLS stream. Before any modeling could happen, I first had to solve the practical issue of getting usable video clips into a local format. That step ended up being its own small engineering project.
After that, the goal was to extract something useful from the film. I wanted to track an individual player through a full play: where Caleb Williams is on each frame, how he moves before the snap, when he escapes the pocket, and how his path changes as the play develops. The broader idea is route and movement data generated directly from film, without relying on manual charting.
Why SAM3
SAM3, Meta’s Segment Anything Model 3, is useful here because it supports text-prompted detection. Given a frame and a prompt such as football player, it can detect and segment the matching objects in the image. For this use case, that removes the need to collect and label an NFL-specific training dataset before doing any player detection.
A more traditional approach would involve training a YOLO-style detector on football broadcast or All-22 footage, then testing how well it generalizes across uniforms, camera angles, stadium lighting, and endzone versus sideline views. SAM3 gives a workable first pass without that setup cost.
The Two-Phase Pipeline
The pipeline runs in two phases.
In the first phase, SAM3 runs on frame 0 of the clip. It detects the visible players and writes a verification image where each detection is labeled as P1, P2, P3, and so on, along with its confidence score. On a Bears vs. Vikings Week 1 play from midfield, it detected 20 players. On a Bears vs. Rams endzone clip, it detected 18 objects, including an aerial camera rig that it labeled as P18 with 0.37 confidence. That one was technically wrong, but also understandable given the shape and placement in the frame.
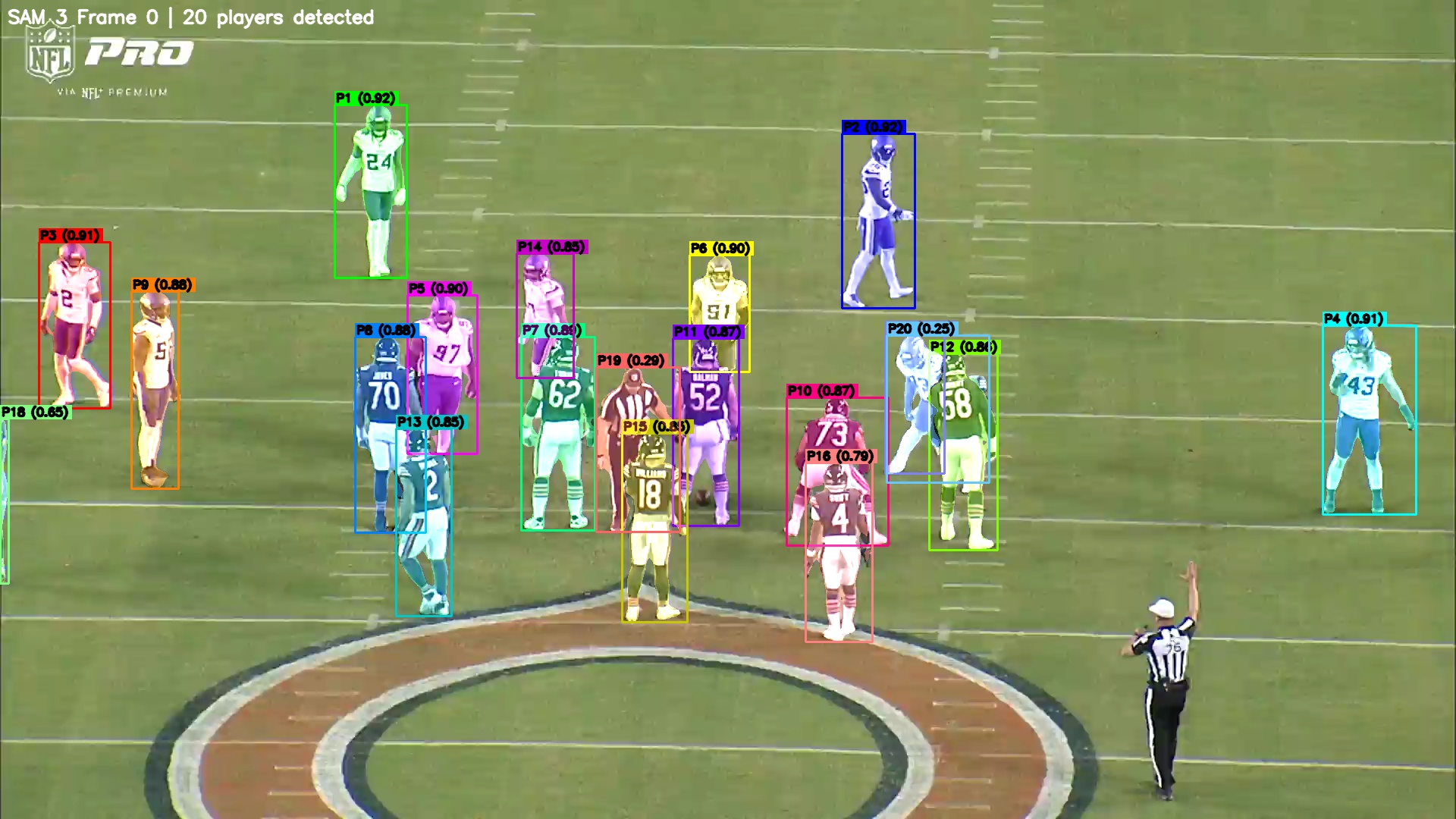
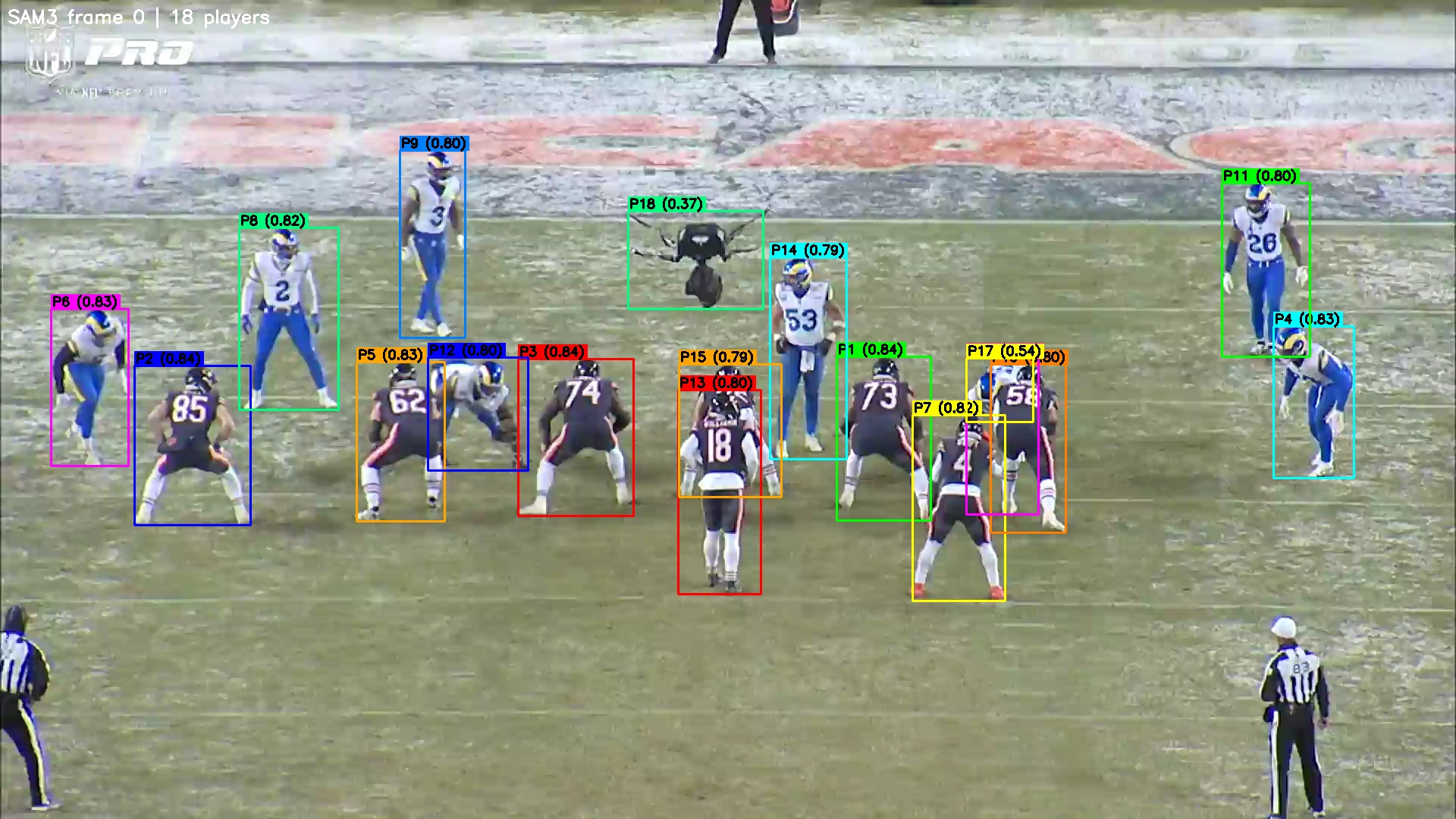
In the second phase, I inspect the verification image, identify the target player by field position, and pass that player index back into the script. SAM2.1 then propagates the selected bounding box through the rest of the video. Its video predictor uses memory-based attention to track the mask over time, which helps with camera movement and partial occlusion.
The first clean run tracked Caleb Williams against the Vikings in Week 1. The clip had 2,015 frames at 59.9 fps, which comes out to about 33 seconds of footage. On an M-series machine, full propagation took roughly 30 minutes.
What Broke
I initially tried using SAM3’s video predictor for the full process. On an M-series Mac mini, this ran into two main issues. The first was a rotary encoding shape mismatch crash on MPS. The second was memory pressure during full-video propagation, which made longer clips unreliable on consumer hardware.
The working architecture uses SAM3 only for text-prompted detection on the first frame. After the target player is selected, SAM2.1 handles the video tracking. The hiera_small SAM2.1 model runs acceptably on MPS when the video and state are offloaded to CPU.
There was also an early initialization issue after swapping in the semantic model. If the predictor is initialized through direct assignment, it can throw an AttributeError because SAM3SemanticModel has no attribute warmup. The fix was to call:
predictor.setup_model(model=sem_model)rather than assigning the model directly.
The other current limitation is player identification. SAM3 usually returns somewhere between 15 and 25 player detections on the first frame, but there is no jersey OCR or roster-aware identification yet. For now, the user has to inspect the verification image, find the target player manually, and pass that index into the tracking step. The process works, but it still depends on human selection at the start of each clip.
The Output
The script produces two main outputs: an annotated MP4 and a JSON file.
The MP4 overlays the tracked mask and bounding box on the original footage, which makes it easy to visually inspect whether the tracker stayed on the correct player. The JSON file stores the per-frame bounding box coordinates and pixel counts.
The JSON is the more important output for downstream analysis. Once the target player has a frame-by-frame path, that data can support route tracing, snap timing, pocket movement analysis, and player path visualization. The tracking holds up reasonably well through camera pans and partial occlusion. It becomes less reliable when the player is fully buried in traffic near the line, which happens often enough in football that it will need a better handling strategy later.
Next Steps
The next major addition is jersey OCR so the target player can be identified automatically. After that, the natural extension is multi-player tracking, ideally all 22 players on the field, followed by route tracing from centroid paths.
The long-term goal is to generate clean per-play movement data from coaching film with as little manual labeling as possible. If that works, it opens up a path toward player-level route data, quarterback movement profiles, and coverage or motion analysis directly from All-22 video.
You’ll need an NFL Pro subscription and an Apple Silicon or CUDA machine for the SAM2.1 propagation step.